| Идеи реализации | ||
|---|---|---|
 | Глава 44. L-системы |  |
| Идеи реализации | ||
|---|---|---|
| | Глава 44. L-системы | |
Перед нами стоит задача запрограммировать класс LSystem,
в котором будут предусмотрены методы для управления L-системой: задания
аксиомы, правил, процедур интерпретации, последовательного циклического её
развития и интерпретации текущего состояния. Кроме этого нужно оснастить
объекты класса LSystem всеми умениями черепахи.
Для выполнения последнего требования имеется три возможности. Во-первых, можно
скопировать файл Turtle.pm под новым именем
LSystem.pm, после чего внести
в LSystem.pm дополнения, посвящённые L-системе. Ещё нужно
не забыть заменить строчку package Turtle на package LSystem. Подобный подход иногда называют
спагетти-кодерством, потому что он
приводит к длинным как спагетти программам. Спагетти-кодерство приведёт к росту
объёма исходного кода программы. Если мы захотим что-то исправить или
усовершенствовать в классе Turtle, нам, пожалуй,
придётся выполнить аналогичные изменения и в классе
LSystem. И, наконец, эта порочная практика противоречит
правилам хорошего программирования, принципу повторного использования кода,
поэтому мы отвергаем её с негодованием.
Вторая возможность называется композицией. Программируя класс
LSystem, предусмотрим в его объектах дополнительное
свойство. значением этого свойства будет объект класса
Turtle; все рисовальные запросы будут впоследствии
адресоваться именно к нему. Таким образом каждый объект
LSystem будет содержать в себе подобъект класса
Turtle. Слово «композиция» буквально переводится как
«составление»: объект составляется из вспомогательных подобъектов. Метод
композиции имеет право на существование, и вполне мог быть реализован в нашей
программе.
Однако мы выбираем третий путь, основанный на наследовании.
Наконец представилась возможность найти достойное применение второму (после инкапсуляции) механизму объектно-ориентированного программирования — наследованию. Наследование позволяет строить одни классы на основе других.
Суть наследования заключается в том, что класс-наследник (назовём его производным) перенимает свойства и методы у одного или нескольких других классов (называемых базовыми). При этом можно управлять тем, какие именно свойства и какие методы нужно унаследовать.
Некоторые объектно-ориентированные языки (например, Java) программирования разрешают лишь единичное наследование. Другие позволяют множественное наследование, то есть ситуацию, когда у производного класса имеется много базовых. Perl допускает множественное наследование.
К чему обязывает наследование? Какие возможности оно открывает? Допустим, класс
ClassX наследует у классов
ClassA, ClassB,
ClassC. Тогда в классе ClassX
открывается доступ к методам его базовых классов. Вызов метода, не
определённого в ClassX, приводит к поиску определения
этого метода в ClassA, а при отсутствии такого
определения в ClassA — у предков класса
ClassA в порядке возрастания их старшинства. Если поиск
в ClassA и его предках не привёл к результату, он
переключается на ClassB, затем на
ClassC, и так далее. Как только метод будет найден, он
вызывается. Отсутствие определения метода в классе и во всех его предках
приводит к фатальной ошибке во время исполнения программы.
Впрочем, производный класс может определить искомый метод самостоятельно, даже если в его базовом классе/классах уже имеется такое определение метода с тем же названием. Эта ситуация называется перегрузкой методов. При помощи перегрузки производный класс может изменить поведение, заложенное в базовом классе.
Типичный сценарий работы с классом LSystem включает
следующие этапы:
LSystem, установка строки-аксиомы,
установка правил;
Этот жизненный цикл объекта класса LSystem даёт
возможность сформулировать систему предписаний класса:
new($axiom%rules
Конструктор. Создаёт и возвращает новый объект класса
LSystem. Принимает строку
$axiom%rules
iterate($n
Осуществляет $n
interpret(%actions
Принимает ассоциативный массив
%actionsLSystem. Осуществляет
интерпретацию текущего состояния L-системы (последовательный вызов процедур
интерпретации для каждого символа, для которого такая процедура определена
в таблице интерпретации).
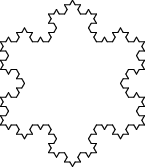
Приводим пример использования класса LSystem в программе
lsystem-koch.pl,
рисующей снежинку Коха:
%perl -Ilib/ bin/lsystem-koch.pl 3* Записан файл: «LSystemKoch3.png» * Размер файла: 3883 * Устройство: pngalpha * Размер: 146×168 * Разрешение: 144 dpi **
При запуске указывается параметр — номер поколения. Он сказывается на
количестве циклов развития L-системы, а также становится частью имени файла
с картинкой: LSystemKoch3.png.
![[Примечание]](admonitions/note.svg) | Примечание |
|---|---|
Запуск программы осуществляется из директории
|
#!/usr/bin/perl use warnings; use LSystem; my $order=shift; my $lsystem=LSystem->new('F++F++F', 'F'=>'F-F++F-F'); $lsystem->iterate($order); $lsystem->setLineWidth(.5); $lsystem->interpret ( 'F'=>sub { shift->forward(72/3**$order) }, '+'=>sub { shift->rotate(60) }, '-'=>sub { shift->rotate(-60) }, ); $lsystem->writePicture("LSystemKoch$order.png", 'pngalpha', 144);
Из примера видно, что для объекта $lsystem класса
LSystem, помимо определённых в этом классе методов
new, iterate,
interpret вызываются также методы
setLineWidth и writePicture
класса Turtle. В этом нет ничего странного — ведь класс
LSystem наследует у класса
Turtle.
Точно так же устроены и другие программы, с помощью которых были получены иллюстрации к этой главе: lsystem-sierpinski.pl (кривая Серпинского), lsystem-dragon.pl (дракон Хартера — Хейтвея), lsystem-gosper.pl (кривая Госпера). Мы не помещаем тексты этих программ на данной странице, ограничившись ссылками.
Обсудим теперь принципы внутреннего устройства класса
LSystem. Как уже было сказано, этот класс полностью
унаследует рисовальные возможности класса Turtle.
Кроме того, объекты класса LSystem дополним свойствами
condition и rules. Первое из свойств
содержит строку состояния L-системы, а второе — ссылку на ассоциативный массив
правил. Эти свойства устанавливаются конструктором класса.
Метод iterate, получив в качестве параметра целое
неотрицательное число, совершит соответствующее количество циклов развития
L-системы (согласно правилам rules), что, возможно,
приведёт к изменению свойства condition.
Метод interpret получает таблицу интерпретации
в качестве списка параметров, а затем интерпретирует строку состояния
condition в соответствии с этой таблицей.
Только что описанная простая реализация класса LSystem
имеет существенный недостаток. Длина строки состояния для многих L-систем имеет
обыкновение расти, и очень быстро. Причиной такого роста служит наличие
строк-последователей в правилах L-системы, имеющих длину и более.
Для примера вспомним L-систему Algæ. Длина строки состояния этой системы в -ом поколении является -м числом Фибоначчи. Как известно, числа Фибоначчи растут довольно быстро с ростом их номера, примерно как геометрическая прогрессия со знаменателем .
От других L-систем можно ожидать ещё более быстрого роста. Возрастание длины строки состояния в геометрической прогрессии опасно катастрофическим переполнением памяти. А для чего мы заставляем строку состояния расти? Чтобы впоследствии, перебирая её символы, интерпретировать их по очереди. Есть ли необходимость держать всю строку состояния в памяти только для того, чтобы обрабатывать символы в ней по одному? Может быть, лучше вычислять очередной символ строки состояния только тогда, когда он понадобится?
Это возможно. Вычисления элементов последовательности по мере необходимости называются ленивыми.
Организовать ленивые вычисления строки состояния L-системы в следующем поколении поможет конвейерный подход. Представим некий объект, который подсоединён к источнику символов и может по мере необходимости потреблять их по одному. На выходе по требованию этот объект может выдавать символы, тоже по одному. Объект должен быть устроен таким образом, чтобы, потребляя символы из строки состояния в -ом поколении L-системы, мог выдавать символы строки состояния в -ом поколении. Будем называть такой объект фильтром.
Фильтр «знает» правила L-системы, а также источник символов, к которому он присоединён. Кроме того, фильтр снабжён внутренним буфером — временным хранилищем символов.
Изучим принцип действия фильтра на примере первого цикла развития L-системы
Algæ, когда аксиома
A превращается в B.
В начале работы фильтр подключен к строке-аксиоме, его буфер пуст. У фильтра
запрашивают первый символ. Фильтр пытается найти символ в буфере, но, напомним,
буфер пуст. Тогда фильтр берёт один символ из его источника (это символ
A), применяет правило AB. Полученную
в результате применения правила строку B фильтр помещает
в свой буфер. Затем первый символ из строки-буфера удаляется, и фильтр выдаёт
его.
Попытаемся взять из фильтра следующий символ. Буфер снова пуст, и фильтр опять обращается к своему источнику. Но теперь все символы из источника взяты, и попытка получить ещё один приводит к взятию неопределённого значения (это значение служит признаком того, что символы в источнике закончились). Фильтру больше неоткуда получать символы — его источник иссяк, а буфер пуст. В таком случае фильтр выдаёт неопределённое значение.
Присоединим к первому фильтру второй, точно такой же. Это означает, что
источником символов для второго фильтра станет первый. Проследим за работой
второго фильтра. При попытке получить символ из него, этот фильтр, обнаружив
пустой буфер, запросит символ из своего источника — это символ
B. Применяя правило BAB, фильтр преобразует
его в строку AB, которая тут же помещается в буфер. Затем из
буферной строки удаляется первый символ (A), и выдаётся по
нашему требованию. В буфере остаётся B. При второй попытке
чтения символа из фильтра выдаётся символ B, который
извлекается из буфера; буфер становится пустым. Третья попытка приводит
к безуспешному поиску символа в пустом буфере, и безуспешному обращению
к источнику, который теперь иссяк. Тогда второй фильтр выдаёт неопределённое
значение, показывая, что он завершил выдачу символов.
Теперь уже понятно, что, соединив фильтров в цепочку-конвейер, и подключив самый первый из них к строке-аксиоме в качестве источника символов, мы сделаем последний фильтр в цепочке источником символов строки состояния в -ом поколении.
| |  | |
| Глава 44. L-системы |  | Разработка |
{kind=link}