| Глава 36. Близость последовательностей | ||
|---|---|---|
 |  | |
| Глава 36. Близость последовательностей | ||
|---|---|---|
| | | |
В этой главе речь пойдёт о сравнении двух конечных последовательностей над одним и тем же алфавитом и об определении степени их сходства или различия.
Такая задача весьма актуальна. Типичная задача в генетике — определение сходства последовательностей, закодированных в ДНК (алфавитом в этом случае служит некоторое множество белков — нуклеотидов, молекулы которых образуют закрученную двойную спираль полимерной молекулы ДНК).
Программы для проверки орфографии, вроде aspell, обнаружив в проверяемом тексте слово, отсутствующее в словаре, предлагают пользователю заменить такое слово на близкое к нему словарное. При этом на выбор предлагается несколько похожих слов из словаря, в порядке убывания их «похожести». Тут роль последовательностей играют слова, а алфавит нужно понимать в обычном смысле.
В поисковых системах близость текста страницы к тексту поискового запроса используется для определения соответствия найденных страниц запросу (релевантности): поисковая выдача упорядочивается по убыванию релевантности.
Близость двух текстов, рассматриваемых как последовательность слов, служит веским аргументом для определения плагиата.
Один из способов определить меру сходства двух последовательностей — найти длину их наибольшей общей подпоследовательности. Подпоследовательностью данной последовательности назовём последовательность, получаемую из данной выбрасыванием некоторого (возможно, нулевого) количества символов.
Общая подпоследовательность всегда существует — пустая подпоследовательность является, очевидно, общей для любых двух последовательностей. Очевидно также существование наибольшей общей подпоследовательности — в неё входят только символы, встречающиеся в обеих последовательностях, а длина не превышает длин сравниваемых последовательностей. Таким образом, множество общих подпоследовательностей является подмножеством конечного множества (множества последовательностей над конечным алфавитом и с ограниченной длиной), и следи них найдётся та (или те), чья длина максимальна. Для краткости вместо слов «наибольшая общая подпоследовательность» будем использовать традиционный акроним LCS — Longest Common Subsequence.
Например, для слов туманы и мутанты
наибольшей общей подпоследовательностью служит таны. Она
получается из первого слова в результате выбрасывания символов
у и м (т╳╳аны), а из
второго — символов м, у
и т (╳╳тан╳ы). Нетрудно видеть, что если
из суммы длин последовательностей вычесть общее количество выброшенных
символов, получится удвоенная длина общей подпоследовательности.
Обратим внимание, что LCS двух последовательностей, вообще
говоря, не единственна. Например, для тех же слов можно предложить и другую
LCS (разумеется, той же длины) — уаны
(╳у╳аны и ╳у╳ан╳ы).
Общее количество выброшенных символов называют расстоянием Левенштейна, или редакторским. Это наименьшее количество редакторских действий, необходимых для превращения одной последовательности в другую. Под редакторскими действиями здесь понимается удаление или вставка символа (вставка символа в первую последовательность равносильна его удалению из второй).
Общее количество выброшенных символов в некторой степени отражает различие двух
последовательностей. Однако естественно считать, что при одном и том же
количестве выброшенных символов более длинные последовательности более похожи,
нежели короткие. Более выразительная мера различия получается, если поделить
количество выброшенных символов на сумму длин последовательностей. Эта величина
всегда заключена на отрезке
,
равна нулю для одинаковых последовательностей, и равна единице для совершенно
разных (не имеющих общих символов). Число, дополняющее эту величину до единицы,
естественно взять в качестве меры сходства двух последовательностей. Слова
туманы и мутанты, таким образом, имеют
сходство
(чуть больше
).
Тот же результат получится, если поделить удвоенную длину
LCS на сумму длин последовательностей.
Помимо нахождения длины LCS, большой интерес представляет
вычисление её самой, или, что равносильно, последовательностей выброшенных
символов. Представим, что имеется две версии одного и того же текста — старая
и новая, имеющие некоторые отличия. Хочется наглядно увидеть их отличия,
выделив их на фоне одинаковых частей. Для примера мы выбрали две версии нашей
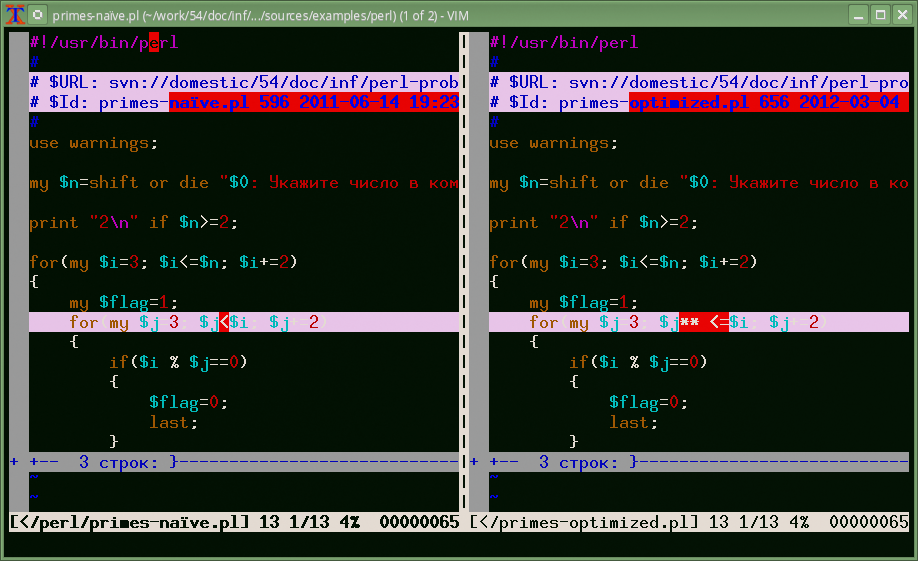
программы, вычисляющей простые числа, primes-naïve.pl
и primes-optimized.pl.
Запускаем команду
%vim -d examples/perl/primes-naïve.pl examples/perl/primes-optimized.pl
Результат виден на рисунке 36.1. «Скриншот команды vim -d». Различающиеся строки подсвечены, а в них красным выделены различия.
Системы версионирования, специальное программное обеспечение, используемое по большей части программистами, также нуждаются в алгоритмах выделения различий в последовательностях. Эти системы позволяют отслеживать историю изменений файлов, сравнивать различные версии, а при необходимости вернуться к более старой версии. Кроме того, многие из них позволяют совместную и одновременную работу разных программистов над файлами, составляющий проект, и слияние внесённых ими изменений. Некоторые системы версионирования (к примеру, RCS, CVS, Subversion) сохраняют версии файла в компактном виде: как последовательность отличий между данной версией и предшествующей ей. Такие отличия называются патчами (от английского patch — заплатка). В результате наложения очередной заплатки получается следующая версия файла.
| | | |
| Готовая программа |  | Идеи реализации |